Bueda API Turns Tags into RDF URIs
Published 14 years ago by Vasco Pedro
![]() A large percentage of content that users deal with on a daily basis is created by other users. Every minute more than 90,000 videos and images are uploaded to YouTube, Flickr and other social media websites, yet this represents a relatively small revenue percentage when compared with traditional media. We believe that one reason for this is the publisher's lack of ability to understand high density content that lacks the adequate description. With mobile platforms providing users with easy methods for rich media upload, this problem will rapidly increase.
A large percentage of content that users deal with on a daily basis is created by other users. Every minute more than 90,000 videos and images are uploaded to YouTube, Flickr and other social media websites, yet this represents a relatively small revenue percentage when compared with traditional media. We believe that one reason for this is the publisher's lack of ability to understand high density content that lacks the adequate description. With mobile platforms providing users with easy methods for rich media upload, this problem will rapidly increase.
Tags are an attempt to mitigate this problem. They allow users an easy way to label content with the labels that make sense to them. Its strengths rely in the simplicity for the user and the ability of the user to use anything as tag, enabling an accurate description of content from the user's perspective. Yet, the strength of tags is also a weakness when it comes to the publisher's ability to understand that content. A tag is, realistically speaking, any sequence of characters. It could be a well formed word, a company name, a person name, an ISBN number, a concatenated version of dates and words, etc. The problem of coverage and disambiguation makes a hard problem to solve.
Bueda addresses this problem by presenting a new solution in the form of an API that can be used by developers to get clean information from noisy tags. It provides a low friction way of tapping into the latest in semantic analysis for tags in a scalable platform.
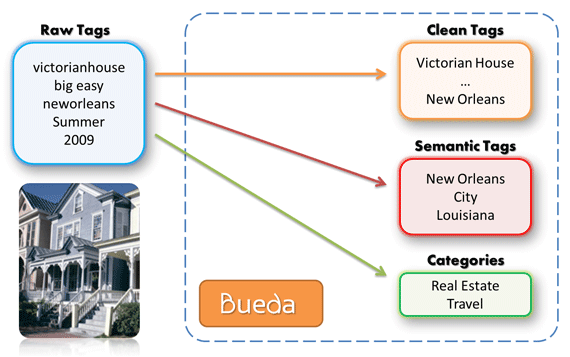
Bueda provides actionable information that enables targeted advertising, content recommendation, search engine optimization and semantic search, amongst other things. Even though the biggest impact might be in high-density content, such as rich media and pictures, the platform is open to any application and use case.
Bueda is a CMU spin-off and uses proprietary technology for Semantic Resource integration, enabling the integration of heterogeneous data sources that enable open domain coverage in a distributed and scalable framework. Bueda is also an Alphalab alum and currently funded by Innovation Works.
Bueda is currently in private beta. However, Semantic Focus readers have access to some exclusive API keys.
About the author

Vasco has extensive experience in the field of computational semantics, having worked at at Google, Honda Research, and Siemens Medical Research.For the last 4 years, his research was focused on Federated Ontology Search and the algorithms needed to overcome the core problems found in integrating knowledge from heterogeneous sources. Vasco holds a PHD and a Masters from Carnegie Mellon University, is a Fulbright Scholar and the Co-founder of Mindkin.com. He is also the author of numerous publications.
Trackback URL for this entry:
http://www.semanticfocus.com/blog/tr/id/976816/
Spam protection by Akismet
Post a comment
Recently Commented Blog Entries